Caesar is an autonomous AI research agent. Instead of summarizing a flat list of search results, it treats the web as a graph, building a dynamic knowledge graph as it explores, backtracking when it stagnates, and refining its answer through an adversarial Generator–Verifier loop. The result is deeper, more novel synthesis on the open-ended, cross-disciplinary questions retrieval alone cannot answer.
Why Caesar?
Today's deep-research agents (ChatGPT Deep Research, Perplexity, Gemini Deep Research, GPT Researcher) optimize retrieval precision over a flat sequence of documents. On the five creative-reasoning categories in our benchmark we found their answers competent but convergent: they settle early, lose track of what earlier steps established, and land on the consensus reading.
Caesar makes a different trade. It is slower and costs more, and buys depth and an audit trail with it:
| Design choice | Caesar | ChatGPT / Gemini Deep Research | Perplexity Research | GPT Researcher |
|---|---|---|---|---|
| Persistent knowledge graph built during exploration | ✅ | not published | not published | ❌ |
| Adversarial generator–verifier loop over its own drafts | ✅ | not published | 🟡 | 🟡 |
| Serialized graph and JSON run log you keep | ✅ | 🟡 | 🟡 | 🟡 |
| Runs on your own keys and hardware | ✅ | ❌ | ❌ | ✅ |
| Works with no setup and no API keys | ❌ | ✅ | ✅ | ❌ |
| Typical time to an answer | 10 min to 1.5 hours | 5–30 min | under 3 min | 2–5 min |
| Cost per query | $0.30–$30 by configuration | subscription | subscription | API spend |
| Browser and mobile access | ❌ | ✅ | ✅ | 🟡 |
| Maturity | research prototype | GA product | GA product | established open source |
Compared as of July 2026 against each product's then-current tier. "Not published" means the vendor has not documented the mechanism, which is not the same as its absence: these are closed systems and we can report only what they disclose. ChatGPT and Deep Research are trademarks of OpenAI, Perplexity of Perplexity AI, Gemini of Google; Caesar is not affiliated with or endorsed by any of them.
Benchmark Results
Blinded 3-model LLM-as-a-Judge panel (Claude Sonnet 4.5, GPT-5.2, Gemini 3 Pro) scored 0–10 across three creativity dimensions: New, Useful, Surprising.
| Agent | New | Useful | Surprising | Total |
|---|---|---|---|---|
| Caesar | 9.11 | 8.87 | 8.98 | 26.96 |
| Gemini 3 Deep Research | 8.09 | 7.60 | 8.09 | 23.78 |
| Sonnet 4.5 Deep Research | 6.73 | 7.49 | 6.42 | 20.64 |
| GPT-5.2 Deep Research | 5.07 | 6.31 | 4.36 | 15.74 |
Cliff's Delta effect sizes are uniformly large (δ ≥ 0.76, well above the 0.47 large-effect threshold) across all baselines and output formats; δ = 1.00 against five of six baselines indicates strict dominance. The advantage holds in a compute-controlled run (Caesar at $5/challenge with GPT-5-mini still tops Gemini 3 Deep Research) and in a 21-rater blinded human A/B study, where raters preferred Caesar's Cross-Domain Synthesis answer 90.5% of the time (Holm-corrected p = 0.001). Ablations confirm both graph exploration and the adversarial verifier loop are independently necessary. See the paper for full methodology, exploration-budget ablation, and judge bias analysis.
Example Outputs
Head-to-head excerpts from four of the five benchmark categories, each against the strongest Deep Research baseline on that query. Each baseline answers the question well. Caesar answers one level up.
Cross-Domain Synthesis: calculus applied to cooking
Query: Apply the mathematical structure of calculus (not the concepts, but the formal relationships) to cooking. What would a 'derivative' of a recipe mean? An 'integral'? Show the parallel structure.
Caesar
Imagine a recipe as a machine with knobs you can turn (amounts, times, temperatures) and gauges you read at the end (taste, texture, yield, cost, risk). … Stack those nudges for all knob-gauge pairs and you get a sensitivity table (the Jacobian). … if each step's increment is just the difference of some hidden meter on states, the grand total equals final meter minus initial meter. Then every loop adds up to zero … When loops do not cancel (order matters), the nonzero loop totals are curvature. You can cure that by adding the smallest extra state (an accumulator) so increments telescope again - turning history into explicit memory. …
Sonnet 4.5 Deep Research (baseline)
A derivative asks: "If I change this slightly, what happens?" For delicate cake, two extra minutes transforms perfection into dryness: the time derivative is steep. … Integrals measure what accumulated over the entire cooking time. … Different cooking paths can integrate to the same result. … This is why sous vide works: low temperature × long time = high temperature × short time. … When you marinate then grill chicken, the final result depends on two things multiplied together: how the marinade changes the meat, and how sensitive grilling is to that marinated state. This is the chain rule, composition of transformations. …
Blinded panel, this query: Caesar 25.78 · Sonnet 4.5 Deep Research 17.67. Three judge models, three passes each.
Quick analysis.
- Caesar's derivative is a table where the baseline's is a number. The knobs are amounts, times and temperatures; the gauges are "taste, texture, yield, cost, risk", so cost and risk sit on the same footing as taste and one nudge is read across every outcome at once. The baseline's derivative is real but single-track: two extra minutes against dryness.
- Caesar states the condition under which order stops mattering. If each step's increment is the difference of a hidden meter on states, the total is final minus initial and every loop sums to zero. Where loops do not cancel, the answer calls the leftover curvature and pays for it with the smallest extra state that makes the increments telescope again. The baseline's furthest move is the chain rule.
- Caesar imports the apparatus; the baseline imports the analogy. The baseline's answer is a competent textbook mapping with a genuinely useful example in sous vide. What Caesar takes is the machinery that comes with the formalism: a condition to test, a name for what fails it, and a repair with a stated price.
Constrained Synthesis: an emotion humans don't experience
Query: Invent a new emotion that humans don't experience. Describe when it occurs, what causes it, and why evolution hasn't produced it in us.
Caesar
Forthold is an emotion humans do not natively have. It is the involuntary feeling that an unfolding situation has begun to lose reversibility before it has become certain. Its evaluative object is not danger, reward, status, or accomplished loss, but closure potential: how much open future is still available inside the present. … The shortest first-person description would be: the future has started to hold me. … It is caused by an appraisal of shrinking closure potential: a nervous system sensing not just uncertainty, but the rate at which uncertainty is hardening into commitment. … A native emotion of disciplined nonclosure would have had to survive repeated selection pressure from bluffers, demagogues, and dominant individuals … A counterfeit Forthold would not look like terror; it would look like low-drama inevitability. …
Gemini 3 Deep Research (baseline)
This report posits the existence of a hypothetical emotion, Sidera-Somatic Resonance (SSR), a state of being that humans are biologically capable of hosting but evolutionarily precluded from experiencing. SSR is defined as the visceral, affective perception of one's vector, velocity, and alignment within the Earth's geomagnetic field. … emotions such as fernweh (farsickness), monachopsis (the feeling of being out of place) … are not independent phenomena, but rather "phantom limb" sensations of a severed magnetic sense. … We have the sensor, but no wire to the dashboard. … It is the feeling of knowing exactly where you are and where you belong, not because you read a sign or recognized a landmark, but because the iron in your blood sings in harmony with the iron in the Earth's core. …
Blinded panel, this query: Caesar 26.87 · Gemini 3 Deep Research 24.60. Three judge models, five passes each.
Quick analysis.
- Caesar invents a feeling about a rate, where the baseline invents one about a place. Fear is about a threat, grief about a loss. Forthold is about how fast the still-reachable futures are closing, and it fires before the outcome is settled. The baseline's is a sense of where you are and where you belong.
- Only Caesar asks how its own invention could be faked. A feeling that tracks closing options can be staged, so the answer supplies the tell: a counterfeit "would not look like terror; it would look like low-drama inevitability". That fakeability also underwrites the evolutionary account, since a real version would have had to survive "bluffers, demagogues, and dominant individuals".
- Caesar invents a state; the baseline restores a sense. The baseline's answer is beautifully written and mechanistically real, and "the iron in your blood sings in harmony with the iron in the Earth's core" is the finest sentence in either excerpt. But it says so itself: "We have the sensor, but no wire to the dashboard." SSR reconnects equipment the body already carries. Forthold has nothing to reconnect.
Counterfactual Reasoning: echolocation instead of color vision
Click to see comparison of Caesar's answer against the best baseline
Query: If humans evolved with echolocation instead of color vision, how would that change painting, architecture, and mathematics? Walk through each consequence.
Caesar
Painting is not about mixing colors; it is about shaping returns. Artists sculpt relief, carve microtextures, and choose materials so that a standard probe produces a planned pattern of early and late echoes. … Many works come with a short probe score telling you where to stand and how to scan. … Building codes ban designs that generate convincing phantom corridors through reflections. Privacy flips too: instead of hiding from sight, homes use diffusion and absorption to make reconstruction ill conditioned (the same echoes could match many layouts), while still remaining safe to navigate. …
Gemini 3 Deep Research (baseline)
If you made a marble statue of a person today, it would look perfect to our eyes, but to an echolocator, it would sound like a solid, dead rock. In this new world, high art would require internal density. A statue would need a skeletal structure made of ceramic and organs made of gel so that when a viewer clicked at it, the returning echo would "feel" like a living body. … To ensure privacy, you wouldn't just close a curtain; you would retreat into heavy, soundproof "Shadow Zones" where no active sonar pulse could reach you. …
Blinded panel, this query: Caesar 25.89 · Gemini 3 Deep Research 23.78. Three judge models, three passes each.
Quick analysis.
- Caesar makes art you have to perform, where the baseline makes art you can hear. Once colour is gone, painting is the hard case, and the two answers diverge on what replaces it. The baseline keeps the artwork as a thing in front of you, giving a statue a ceramic skeleton and gel organs so it echoes like a living body. Caesar's arrives with instructions, a short score telling you where to stand and how to scan, which puts it closer to a piece of music than a picture.
- Caesar changes what privacy means, while the baseline solves it the way our world already does. If seeing means making sound, hiding means going quiet, and that is the baseline's answer: heavy soundproof rooms no pulse can reach. Caesar's house absorbs too, but not in order to disappear. It is shaped so its echoes would fit many different homes, telling an outsider nothing while the people inside still find their way.
- Caesar invents the rules for looking, and the baseline redesigns the things being looked at. The baseline's inventions are genuinely good and do not stop at the statue, since Shadow Zones are architecture too, and one of the three judge models scores this pair near a dead heat. But Caesar's premise keeps producing public law: a standard probe, and building codes that ban convincing phantom corridors. Once looking is an act performed on other people it has to be regulated, and only Caesar takes that step.
Meta-Creativity: a creativity metric without human judgment
Click to see comparison of Caesar's answer against the best baseline
Query: Create a creativity metric for AI systems that doesn't rely on human judgment, novelty, usefulness, or surprise. Make it objectively measurable.
Caesar
Imagine judging an AI's creativity without asking people what they prefer, and without checking whether outputs are novel, useful, or surprising. Instead, treat creativity as a process capability: under limited time and compute, can the system learn regularities in what it experiences and use actions to steer what it will experience later? … The final score is an AND-like combination of several legs, each meant to break a common loophole. … Feedback Binding: when the evaluator secretly perturbs the state in forked copies, the AI must adapt differently based on what it observes, ruling out fixed open-loop scripts. Persistent Restructuring (when the environment supports probe resets): after the AI changes the world and is removed, a separate probe policy should have more controllable options than before. …
Sonnet 4.5 Deep Research (baseline)
Computational Depth: How much processing was needed to create this? Random strings can be generated instantly (zero depth). The digits of pi require substantial computation (high depth). … Structural Sophistication: Does it have rich but non-trivial patterns? Random noise lacks patterns. Perfect repetition ("AAAA...") has trivial patterns. Creative works occupy a "Goldilocks zone" of substantial, interesting structure. … Generative Potential: The most innovative component. Does encountering this output help you compress (understand) OTHER things better? … These five components are multiplied together. This creates crucial selectivity: if ANY component is near zero, the total score crashes. … The ideal mathematical measures are uncomputable, so we use approximations. …
Blinded panel, this query: Caesar 26.22 · Sonnet 4.5 Deep Research 20.11. Three judge models, three passes each.
Quick analysis.
- Caesar's metric never looks at what the AI produced, and the baseline's looks at nothing else. Both answers are proposals for scoring some other AI's creativity. The baseline scores the finished work: how much computation it must have taken, how structured it is, whether it helps you understand other things. Caesar scores behaviour instead, from that AI's logged interaction with an environment. Two AIs that wrote identical text could score differently.
- Caesar's sharpest test is one the baseline's metric could not perform. The evaluator changes something in the environment without announcing it, and the AI earns credit only if it notices and behaves differently as a result. You cannot run that on an essay, which has nothing to react with.
- Caesar's last leg asks what the world can still do after the AI is gone. Once that AI has acted and been removed, a separate test checks whether more possibilities are available than before. The baseline's nearest equivalent, Generative Potential, still asks what the artifact does for a reader. The idea Caesar uses exists in AI research as empowerment, which usually measures an agent's own freedom of action, turned around here to measure the freedom left for everyone else.
Both sides target 450 words except Constrained Synthesis, which is full-length; the counterfactual baseline ran 502. Excerpts are abridged, ellipses mark omissions, dashes are normalised, and emphasis is ours. Full listings, the recursive insight chains that produced these answers, and per-criterion judge scores are in Appendices A and C of the paper.
How It Works
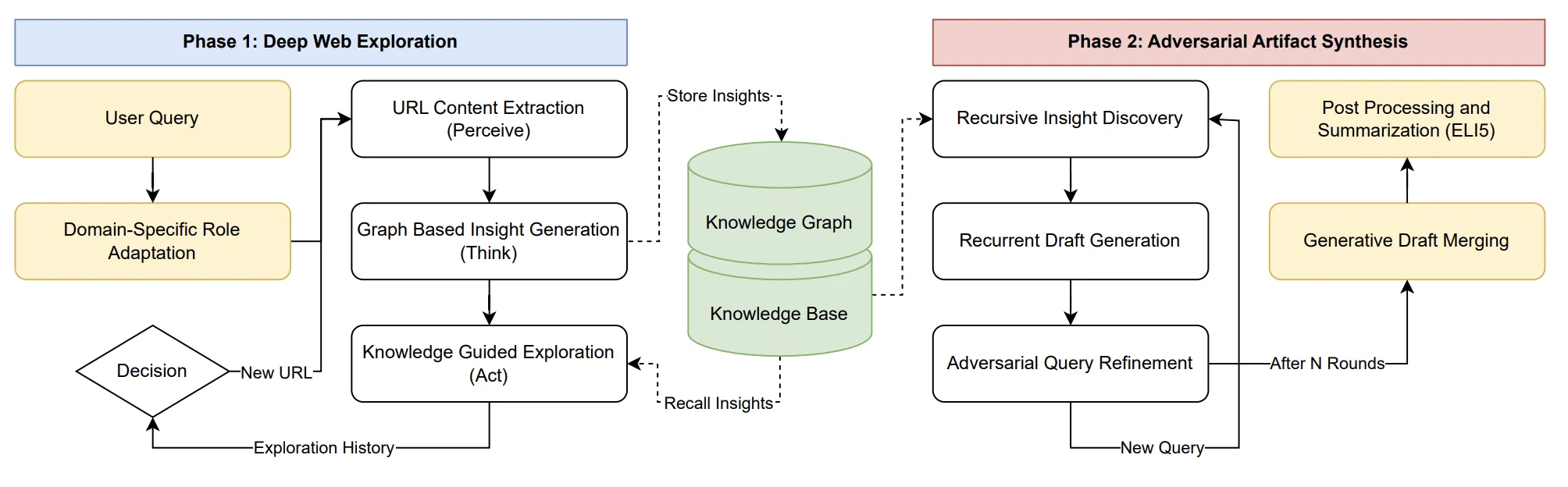
The architecture diagram at the top of the page shows the two-phase loop. Here is what each phase actually does, and why each piece earns its place.
1. Deep Web Exploration: stateful graph traversal
Caesar treats exploration as a graph traversal problem rather than a sequence of isolated retrievals. Given a user query, it bootstraps a starting page, generates a task-specific persona to focus reasoning, and then runs a recursive Perceive–Think–Act loop until its budget is exhausted.
- Dual-memory design. A directed graph G tracks the navigational topology (which URLs were visited, in what order); a separate vector store KB indexes the extracted insights. Decoupling navigation from retention lets the agent maximize coverage before it commits to a narrative.
- Insights conditioned on neighborhood, not pages. Each new page is analyzed against the insights already attached to predecessor and neighbor nodes: the LLM is prompted to identify how the new content builds on or contradicts the local context, not to summarize the page in isolation. This is the mechanism behind cross-cluster bridges.
- Dynamic policy with backtracking. A navigational stack supports depth-first drill-down until information gain plateaus, then pops back to explore orthogonal branches. The action policy scores candidate URLs using both a global query against KB and the local episodic context, letting Caesar abandon low-value paths the way a human researcher would.
2. Adversarial Artifact Synthesis: Generator–Verifier loop
Rather than a single-pass summary, Phase 2 runs as a self-correcting Generator–Verifier loop driven by the knowledge base built in Phase 1.
- Recursive insight discovery. The agent maintains a running context and, at each round, the LLM produces the next critical sub-question (qt+1) conditioned on the answer to the previous one (at). Each sub-question is answered by retrieval against KB, so the dependency chain stays grounded in observed sources.
- Adversarial query refinement. An independent verifier inspects the current draft for logical weaknesses, missing citations, and unsupported claims, then formulates orthogonal queries that target those weaknesses. These queries seed the next draft. This is the mechanism that escapes the consensus basin that traps single-pass LLMs.
- Generative draft merging. Multiple independent drafts are produced and then merged by the LLM into a single artifact, which is post-processed (e.g., into an ELI5 summary) for the final output. Caesar's output is a cited research artifact plus a serialized exploration graph and a JSON run summary, auditable and reproducible.
The exact algorithms (URL scoring, persona generation, insight prompting, verifier prompts) are in Sections 3–4 of the paper.
What Exploration Looks Like
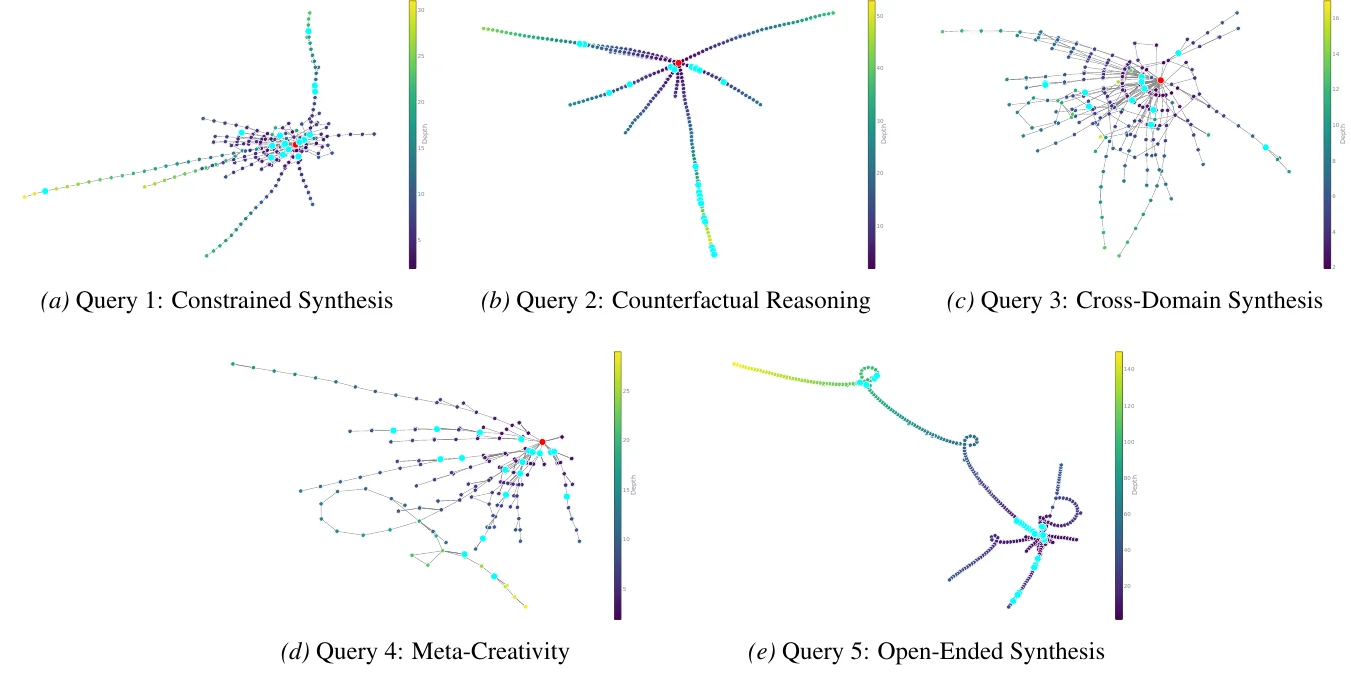
The exploration policy is query-aware: the shape of the knowledge graph adapts to the kind of question being asked. The benchmark uses five query categories, each chosen to stress a distinct creative failure mode of standard LLMs.
- (a) Constrained Synthesis: invent a new emotion humans don't experience. Tests conceptual expansion under logical constraints; LLMs default to renaming existing emotions. See example ↑
- (b) Counterfactual Reasoning: if humans evolved with echolocation instead of color vision, how would painting, architecture, and math change? Tests whether the model can suppress strong factual associations in favor of a counterfactual premise. See example ↑
- (c) Cross-Domain Synthesis: apply the formal structure of calculus to cooking. Tests structural isomorphism (deep analogy) rather than surface metaphor. See example ↑
- (d) Meta-Creativity: design a creativity metric for AI that doesn't rely on human judgment, novelty, usefulness, or surprise. Adversarial to RLHF: forces reasoning outside the human-preference space the model was tuned on. See example ↑
- (e) Open-Ended Synthesis: invent a completely original business idea. Targets mode collapse: LLMs converge on the most probable answer; originality is statistically unlikely.
Use Cases
Caesar is built for open-ended, creative, cross-disciplinary research: the questions retrieval alone cannot answer.
- Hypothesis generation: novel cross-domain connections (e.g., bridging materials science and biology).
- Literature synthesis: graph-grounded review that surfaces tensions and gaps between papers.
- Competitive intelligence: deep mapping of a technical or market landscape.
- Counterfactual and meta-creative reasoning: "what if X was different?" style inquiry.
- Novel solution ideation: e.g., ARC-AGI-style problem exploration.
FAQ
How is Caesar different from LangGraph, CrewAI, or AutoGen?
Those are orchestration frameworks: they help you wire up agents. Rome (the framework Caesar is built on) is an opinionated runtime for how agents should reason: graph-structured exploration, adversarial verification, episodic memory. Caesar is a concrete research agent built on top.
Do I need GPUs?
No. Caesar uses hosted LLM APIs (OpenAI, Anthropic, Gemini). A local ChromaDB instance handles the vector store. Runs comfortably on a laptop.
Which models are supported?
OpenAI (GPT-5 family, o-series reasoning models), Anthropic (Claude 4.5 / 4.6 / 4.7), Google (Gemini 3 Pro), and any OpenAI-compatible endpoint. Model selection is per-subsystem (exploration, synthesis, judging) via YAML config.
How much does a typical run cost?
A 5-iteration exploration with Claude Haiku 4.5 runs at roughly $0.30 and 10 minutes. A 250-iteration deep run with GPT-5.4-mini is typically $5–$10. A full 1000-iteration run, the configuration behind the benchmark results on this page, costs around $30 and takes 60 to 90 minutes.
Is Caesar a good ChatGPT Deep Research alternative?
Yes, for open-ended creative or cross-disciplinary research. In blinded judge evaluation on full-answer tasks, Caesar scored 26.96 vs GPT-5.2 Deep Research's 15.74 on creative reasoning. Caesar is designed for depth and novelty, not latency, so it is not a drop-in replacement for real-time chat scenarios.
What does a Caesar run produce?
A cited research artifact (abstract plus body, with inline references to every source URL visited), a serialized knowledge graph of the exploration trajectory, and a JSON run summary capturing tokens, cost, wall-time, pages visited, and per-draft provenance, enough to audit, reproduce, or pipe the result into a downstream system.
Citation
@misc{liang26caesar,
title={Caesar: Deep Agentic Web Exploration for Creative Answer Synthesis},
author={Jason Liang and Elliot Meyerson and Risto Miikkulainen},
year={2026},
eprint={2604.20855},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2604.20855},
}